Debugging PySpark¶
PySpark uses Spark as an engine. PySpark uses Py4J to leverage Spark to submit and computes the jobs.
On the driver side, PySpark communicates with the driver on JVM by using Py4J.
When pyspark.sql.SparkSession or pyspark.SparkContext is created and initialized, PySpark launches a JVM
to communicate.
On the executor side, Python workers execute and handle Python native functions or data. They are not launched if a PySpark application does not require interaction between Python workers and JVMs. They are lazily launched only when Python native functions or data have to be handled, for example, when you execute pandas UDFs or PySpark RDD APIs.
This page focuses on debugging Python side of PySpark on both driver and executor sides instead of focusing on debugging with JVM. Profiling and debugging JVM is described at Useful Developer Tools.
Note that,
If you are running locally, you can directly debug the driver side via using your IDE without the remote debug feature. Setting PySpark with IDEs is documented here.
There are many other ways of debugging PySpark applications. For example, you can remotely debug by using the open source Remote Debugger instead of using PyCharm Professional documented here.
Remote Debugging (PyCharm Professional)¶
This section describes remote debugging on both driver and executor sides within a single machine to demonstrate easily. The ways of debugging PySpark on the executor side is different from doing in the driver. Therefore, they will be demonstrated respectively. In order to debug PySpark applications on other machines, please refer to the full instructions that are specific to PyCharm, documented here.
Firstly, choose Edit Configuration… from the Run menu. It opens the Run/Debug Configurations dialog.
You have to click + configuration on the toolbar, and from the list of available configurations, select Python Debug Server.
Enter the name of this new configuration, for example, MyRemoteDebugger and also specify the port number, for example 12345.
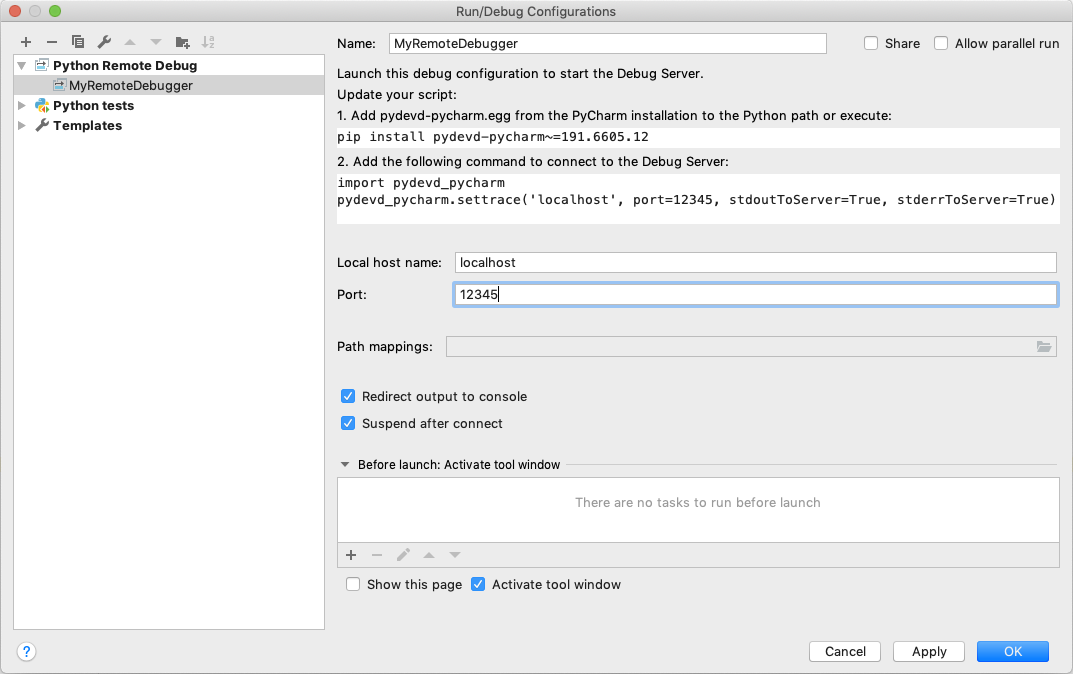
pydevd-pycharm package in all the machines which will connect to your PyCharm debugger. In the previous dialog, it shows the command to install.pip install pydevd-pycharm~=<version of PyCharm on the local machine>
Driver Side¶
To debug on the driver side, your application should be able to connect to the debugging server. Copy and paste the codes
with pydevd_pycharm.settrace to the top of your PySpark script. Suppose the script name is app.py:
echo "#======================Copy and paste from the previous dialog===========================
import pydevd_pycharm
pydevd_pycharm.settrace('localhost', port=12345, stdoutToServer=True, stderrToServer=True)
#========================================================================================
# Your PySpark application codes:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).show()" > app.py
Start to debug with your MyRemoteDebugger.

spark-submit app.py
Executor Side¶
To debug on the executor side, prepare a Python file as below in your current working directory.
echo "from pyspark import daemon, worker
def remote_debug_wrapped(*args, **kwargs):
#======================Copy and paste from the previous dialog===========================
import pydevd_pycharm
pydevd_pycharm.settrace('localhost', port=12345, stdoutToServer=True, stderrToServer=True)
#========================================================================================
worker.main(*args, **kwargs)
daemon.worker_main = remote_debug_wrapped
if __name__ == '__main__':
daemon.manager()" > remote_debug.py
You will use this file as the Python worker in your PySpark applications by using the spark.python.daemon.module configuration.
Run the pyspark shell with the configuration below:
pyspark --conf spark.python.daemon.module=remote_debug
Now you’re ready to remotely debug. Start to debug with your MyRemoteDebugger.
spark.range(10).repartition(1).rdd.map(lambda x: x).collect()
Checking Resource Usage (top and ps)¶
The Python processes on the driver and executor can be checked via typical ways such as top and ps commands.
Driver Side¶
On the driver side, you can get the process id from your PySpark shell easily as below to know the process id and resources.
>>> import os; os.getpid()
18482
ps -fe 18482
UID PID PPID C STIME TTY TIME CMD
000 18482 12345 0 0:00PM ttys001 0:00.00 /.../python
Executor Side¶
To check on the executor side, you can simply grep them to figure out the process
ids and relevant resources because Python workers are forked from pyspark.daemon.
ps -fe | grep pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
...
Profiling Memory Usage (Memory Profiler)¶
memory_profiler is one of the profilers that allow you to check the memory usage line by line. This method documented here only works for the driver side.
Unless you are running your driver program in another machine (e.g., YARN cluster mode), this useful tool can be used
to debug the memory usage on driver side easily. Suppose your PySpark script name is profile_memory.py.
You can profile it as below.
echo "from pyspark.sql import SparkSession
#===Your function should be decorated with @profile===
from memory_profiler import profile
@profile
#=====================================================
def my_func():
session = SparkSession.builder.getOrCreate()
df = session.range(10000)
return df.collect()
if __name__ == '__main__':
my_func()" > profile_memory.py
python -m memory_profiler profile_memory.py
Filename: profile_memory.py
Line # Mem usage Increment Line Contents
================================================
...
6 def my_func():
7 51.5 MiB 0.6 MiB session = SparkSession.builder.getOrCreate()
8 51.5 MiB 0.0 MiB df = session.range(10000)
9 54.4 MiB 2.8 MiB return df.collect()
Identifying Hot Loops (Python Profilers)¶
Python Profilers are useful built-in features in Python itself. These provide deterministic profiling of Python programs with a lot of useful statistics. This section describes how to use it on both driver and executor sides in order to identify expensive or hot code paths.
Driver Side¶
To use this on driver side, you can use it as you would do for regular Python programs because PySpark on driver side is a regular Python process unless you are running your driver program in another machine (e.g., YARN cluster mode).
echo "from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).show()" > app.py
python -m cProfile app.py
...
129215 function calls (125446 primitive calls) in 5.926 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1198/405 0.001 0.000 0.083 0.000 <frozen importlib._bootstrap>:1009(_handle_fromlist)
561 0.001 0.000 0.001 0.000 <frozen importlib._bootstrap>:103(release)
276 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
276 0.000 0.000 0.002 0.000 <frozen importlib._bootstrap>:147(__enter__)
...
Executor Side¶
To use this on executor side, PySpark provides remote Python Profilers for
executor side, which can be enabled by setting spark.python.profile configuration to true.
pyspark --conf spark.python.profile=true
>>> rdd = sc.parallelize(range(100)).map(str)
>>> rdd.count()
100
>>> sc.show_profiles()
============================================================
Profile of RDD<id=1>
============================================================
728 function calls (692 primitive calls) in 0.004 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
12 0.001 0.000 0.001 0.000 serializers.py:210(load_stream)
12 0.000 0.000 0.000 0.000 {built-in method _pickle.dumps}
12 0.000 0.000 0.001 0.000 serializers.py:252(dump_stream)
12 0.000 0.000 0.001 0.000 context.py:506(f)
...
This feature is supported only with RDD APIs.